In today’s era of big data, real-time decision-making, and AI-powered insights, enterprises must ensure that data moves frictionlessly from source systems to analytical platforms. Zero Friction Data Ingestion is an architectural approach that minimizes latency, manual transformations, and operational bottlenecks—allowing organizations to unlock immediate value from their data assets. This makes the data available, where it is needed and when it is needed, enabling the shortest zero-distance between decision making and the data used for making those decisions.
This article explores the technical patterns, methods, tools, and real-world examples that enable Zero Friction Data Ingestion, covering concepts like Schema-on-Read, Data Lakes, Lakehouses, Change Data Capture (CDC), and event-driven ingestion.
Understanding Zero Friction Data Ingestion
What is Zero Friction Data Ingestion?
Zero Friction Data Ingestion refers to the seamless ingestion of data into storage and processing systems with:
-
Minimal upfront transformations (shift from ETL to ELT or EL). In the traditional ETL approach, data is first extracted from source systems, then transformed (cleaned, shaped, integrated, aggregated) in a staging area, and finally loaded into the target data warehouse or reporting system; the (E)xtract, (T)ransform and (L)oad sequence. This sequence and the associated software components are tightly coupled with a predefined schema (both source and target) and therein lies the development and operational complexity to enforce this schema.
In contrast, ELT reverses the order of the last two steps. Data is extracted from source systems, loaded directly into a scalable storage like a data lake or lakehouse with minimal or no transformations, and then transformed within the target environment as needed for specific analytical use cases effectively shifting the availability of data to the business teams and empowering them. This reduction of the lead time of data availability, shifts control of usage of data to the business teams.
-
Automated validation and metadata governance
Automation to manage two critical aspects of data management: data quality (validation) and effectively governing the information about the data itself (metadata) are enabling practices for this pattern.
-
Support for heterogeneous data types
Support for structured, semi-structured, unstructured to enable this practice, this is the ability of modern data systems, particularly data lakes and lakehouses, to handle a wide variety of data formats and structures without requiring them to be conformed to a single, rigid schema upfront.
This support can include:
- Structured Data: Data organized in a tabular format with rows and columns, like data from relational databases (e.g., CSV, Parquet, Avro).
- Semi-structured Data: Data that has some organizational properties but lacks a strict schema, such as JSON, XML, and log files.
- Unstructured Data: Data that does not conform to a predefined format, such as text documents, images, audio files, and video files.
-
High scalability and resilience for large-scale, distributed systems
This is both an enabling capability and technique which supports this pattern. This includes the ability to handle large volumes and velocities of data, preventing ingestion pipelines from becoming overwhelmed and introducing delays or friction along with fault-tolerant systems to minimize downtime and data loss, providing a reliable and uninterrupted ingestion experience. Users should not have to worry about data not being ingested due to system failures.
Why is this important ?
-
Accelerated Time-to-Insight
Immediate access to raw data in a data lake or lakehouse allows data scientists and analysts to quickly explore new datasets and test hypotheses without waiting for lengthy ETL processes. This accelerates the experimentation cycle, leading to quicker identification of valuable insights.
When developing new products, features, or marketing campaigns, the ability to rapidly analyze raw customer data, market trends, and operational metrics allows for faster prototyping and validation of ideas. This reduces the time spent on assumptions and increases the likelihood of launching successful offerings.
Real-time access to data streams enables businesses to identify emerging market trends, customer behavior shifts, or potential operational issues much faster. This agility allows for quicker responses, capitalizing on opportunities or mitigating threats before they significantly impact the business and its time to market for relevant solutions.
-
Reduced Operational Complexity
Manual data wrangling is a time-consuming and resource-intensive process. It involves data cleaning, transformation, and preparation, often performed by skilled data professionals. This manual effort directly contributes to delays in obtaining actionable insights and, consequently, improves the lead time.
Automation of validation and metadata governance significantly reduces the manual effort required to ensure data quality and understand its context. This accelerates the data preparation phase, making data analysis-ready much sooner and shortening the time to derive insights.
Improvement in the efficiency of resource allocation by automating data wrangling tasks, data scientists and analysts can focus on higher-value activities like analysis, model building, and generating strategic recommendations. This efficient allocation of resources can speed up the overall insight generation process, contributing to a faster lead times for data-driven initiatives.
Manual data wrangling is prone to human error, which can lead to inaccurate insights and the need for rework. Automation improves data consistency and reliability, reducing the time spent on correcting mistakes and ensuring that insights are based on trustworthy information, thus accelerating the path to actionable outcomes and market impact.
-
Enhanced Data Agility
Traditional ETL, with its rigid upfront schema and transformation definitions, struggles to adapt to changing data sources, evolving business needs, and new analytical questions. This lack of agility can significantly delay the time it takes to obtain insights relevant to new market dynamics or strategic pivots, thereby improving Lead Time To Market.
Schema-on-Read architectures and the ability to handle heterogeneous data types allow for quicker ingestion of new data sources and adaptation to evolving data models without lengthy schema redesigns and pipeline rebuilds. This agility ensures that the insights needed to inform time-sensitive market decisions can be obtained rapidly.
When new business questions arise, the ability to directly query and analyze raw data in a flexible data lake or lakehouse environment, without being constrained by predefined ETL transformations, allows for faster exploration and insight generation. This responsiveness is crucial for making timely decisions that impact Lead Time for new products or strategies.
Providing users with access to governed raw or minimally transformed data, along with automated tools for validation and understanding, enables self-service analytics. This reduces the reliance on centralized data engineering teams for every new analytical request, democratizing access to insights and accelerating the time it takes for business users to find answers.
-
Cost Optimization
Product cost optimizations are fundamental to performing data management on the cloud. In conventional high friction data ingestion architectures, inefficient data pipelines with extensive upfront transformations often lead to significant data reprocessing and movement, increasing operational costs and indirectly impacting the lead time to data insights by consuming resources that could be used for faster analysis and deployment.
Impact on Lead Time to Insights; faster iteration cycles, by minimizing reprocessing and data movement, data teams can iterate on their analyses and models more quickly. This faster feedback loop accelerates the refinement of insights and the development of actionable strategies, ultimately reducing the time to bring data-driven products or features to market or to the customer.
Improved focus on Value-Added activities through efficient data ingestion and management frees up budget and resources that can be reinvested in activities directly contributing to faster lead times, such as accelerating development cycles, improving marketing strategies based on quicker insights, or streamlining deployment processes.
High scalability and resilience ensures that the data ingestion and analysis infrastructure can handle growing data volumes and evolving needs without requiring costly over-provisioning or frequent re-architecting. This cost efficiency supports sustained agility and faster lead times in the long run.
Core Patterns Enabling Zero Friction Data Ingestion
1. Schema-on-Read vs. Schema-on-Write
These are the two key techniques which are key to understanding the Zero Friction Data Ingestion pattern of which the Schema-on-Read is the enabling pattern used by the Data Lake and Lake House storage architecture patterns
Schema-on-Write (Conventional Approach)
- Enforces schema validation before data is stored.
- Common in traditional data warehouses (e.g., Oracle, SQL Server, Teradata).
- Challenges:
- Inflexible to evolving data models.
- High upfront data modeling effort.
Schema-on-Read (Modern Approach)
- Stores raw data as-is without enforcing schema at ingestion.
- Schema is dynamically applied at query time.
- Tools:
- Data Lakes: Amazon S3, Azure Data Lake Storage Gen2, HDFS.
- Query Engines: Apache Hive, Presto, Trino, Dremio, Apache Iceberg, Delta Lake.
Let’s capture the key differences:
| Aspect | Schema-on-Write | Schema-on-Read |
|---|---|---|
| When Applied | Before ingestion | At query time |
| Friction Level | High (requires transformation upfront) | Low (raw data accepted immediately) |
| Best For | Stable, well-defined data | Exploratory analytics, evolving sources |
| Latency | Higher (ETL delay) | Near-zero (direct landing) |
The technique of Schema-on-Read directly supports Zero Friction Ingestion pattern by eliminating the bottlenecks in data ingestion by:
- Eliminating ETL bottlenecks (no transformations before storage).
- Enabling real-time ingestion (data lands immediately in raw form).
- Reducing governance overhead (schema validation happens later).
2. Data Lakes and Lakehouses
These are storage architecture which enable the Zero Friction Ingestion architecture pattern.
Data Lakes
- Centralized storage repositories that accept structured, semi-structured, and unstructured data.
Lakehouses (Evolution)
- Combine the best of data lakes (low-cost storage) and data warehouses (ACID transactions, performance optimizations).
3. Event-Driven Ingestion: Kafka, Pulsar, and Kinesis
Modern ingestion pipelines are often event-driven, reacting to changes in source systems instantly. Event-driven ingestion is a core technique that directly enables the Zero Friction Data Ingestion pattern by eliminating batch processing delays, manual intervention, and rigid pipeline dependencies.
This technique decouples Producers from Consumers which is a fundamental Zero Friction Principle.
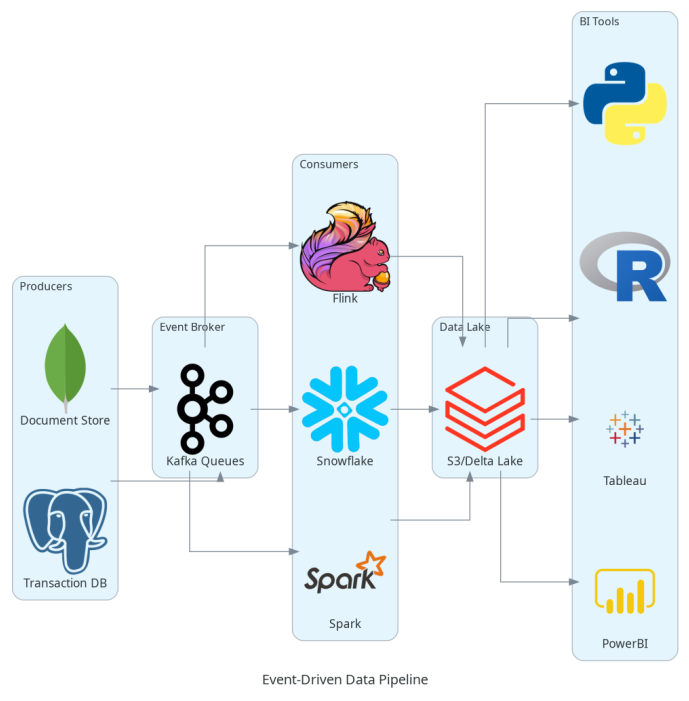
** Architecture Example: **
Debezium (open-source CDC tool) captures changes from a PostgreSQL database and streams them to Kafka. Spark Structured Streaming then processes and writes to Delta Lake, making new data queryable instantly.
4. Change Data Capture (CDC)
Capturing only incremental changes—rather than full table snapshots—minimizes friction and resource consumption.
Examples: An leading healthcare insurance company uses Debezium to detect changes in policyholder databases (PostgreSQL) and replicate them in near real-time to a Azure Data Lake for downstream analytics.
5. Data Contracts and Automated Validation
Benefits:
- Shifts data quality left (proactive validation).
- Prevents downstream breakages due to schema drift.
Examples:
When ingesting customer onboarding forms (JSON) into an Azure Blob Storage, Great Expectations validates mandatory fields and data types before allowing them into production datasets.
Recommended implementation
- Start with Schema-on-Read for new data sources
General implementation happens by ingesting data in native format (JSON, CVS, Avro, Parquet) into cloud storage S3, ADLS or GCS. This is followed by using Query Engines like Athena, BigQuery or Spark SQL to interpret schemas at run time. The benefit of doing it this way is two fold; Data is available immediately on landing and the ingestion pipeline doesn’t break with new fields etc.
- Gradually enforce critical schemas via contracts
Constraints are applied only when needed so that the balance between flexibility and governance is maintained. Data contracts are developed and implemented only on mission critical datasets. Observability is a key concern here to detect schema drift.
- Use Delta Lake/Iceberg for flexibility
“Open Table Formats” like Delta Lake from Databricks and Apache Iceberg is used for ACID compliance and maintaining historical versions of data.
Tools which enable the Zero Friction Ingestion pattern
Below are some of the tools which can be used for enabling this pattern at the enterprise level. Strong pipeline management along with monitoring and governance is an absolute must while enabling this pattern. We have to keep in mind that we are enable access to data where the decisions are taken, and frequently where the data originates, ensuring strong security is of utmost importance while enabling this pattern.
| Functionality | Tools |
|---|---|
| Batch ingestion | Apache NiFi, Airbyte, Fivetran (SaaS) |
| Streaming ingestion | Apache Kafka, Apache Pulsar, Redpanda |
| Metadata management | Apache Atlas, Amundsen, OpenMetadata |
| Data Transformation | dbt (for ELT), Spark SQL, Trino |
| Storage | Apache Hudi, Delta Lake, Iceberg |
| Monitoring & Governance | Great Expectations, OpenLineage |
Implementation Roadmap for Enterprises
A very high level implementation roadmap will look like the table below. I have included the new entrants into the Enterprise Data Management landscape like Apache Hudi.
| Step | Action | Recommended Tools |
|---|---|---|
| 1 | Catalog existing and new data sources (streaming, batch) | Airbyte, Apache Nifi |
| 2 | Choose storage architecture (Data Lake vs. Lakehouse) | S3 + Apache Hudi, Delta Lake |
| 3 | Implement Schema-on-Read ingestion | Apache Hive, Trino, Presto |
| 4 | Real-time processing pipeline | Kafka + Spark Structured Streaming |
| 5 | Automated Data Validation | dbt + Great Expectations |
| 6 | Connect analytics & ML tools | Tableau, Power BI, Superset, JupyterHub |
Conclusion
Zero Friction Data Ingestion is not a luxury—it is foundational for organizations aiming to thrive in a real-time, AI-driven future.
By adopting the following architectural patterns :
- Schema-on-Read architectures for agility
- Data Lakes and Lakehouses for scalable storage
- Event-driven pipelines for real-time responsiveness
and enabling techniques and methods like
- CDC and data contracts for reliability
enterprises can deliver faster insights, improve data quality, and dramatically reduce operational burdens.
What’s Next to enable this pattern ?
- Conduct a gap assessment of your current ingestion workflows.
- Pilot a Lakehouse architecture (e.g., Delta Lake or Apache Hudi).
- Introduce event-driven ingestion using Kafka and real-time CDC.
#DataEngineering #DataLakes #Lakehouse #Kafka #CDC #SchemaOnRead #OpenSource #ZeroFriction